



Global Resources
With extensive experience in speech recognition, Nexdata has resource pool covering more than 50 countries and regions and provides data collection and annotation of hundreds of languages.
Please fill in your name
Mobile phone format error
Please enter the telephone
Please enter your company name
Please enter your company email
Please enter the data requirement
Successful submission! Thank you for your support.
Format error, Please fill in again
Confirm
The data requirement cannot be less than 5 words and cannot be pure numbers
m.nexdata.datatang.com

With extensive experience in speech recognition, Nexdata has resource pool covering more than 50 countries and regions and provides data collection and annotation of hundreds of languages.
Our linguist team works closely with clients to assist them with dictionary and text corpus construction, speech quality inspection, linguistics consulting and etc.

Nexdata is equipped with professional recording equipment and has resources pool of 50+ countries and regions, and provide various types of speech data collection and annotation serivces.





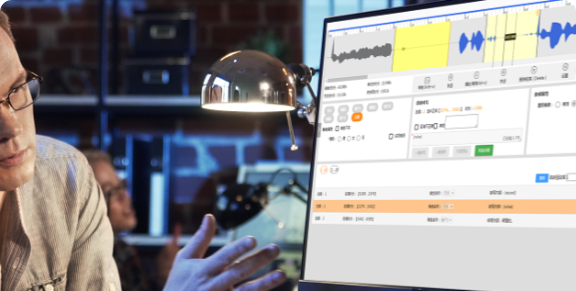
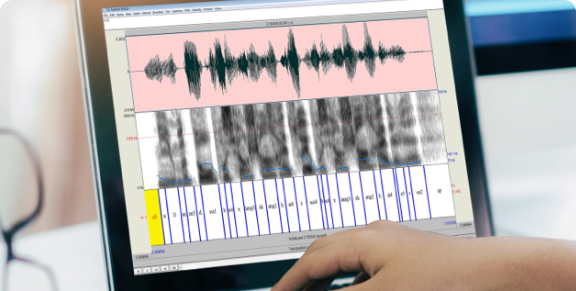
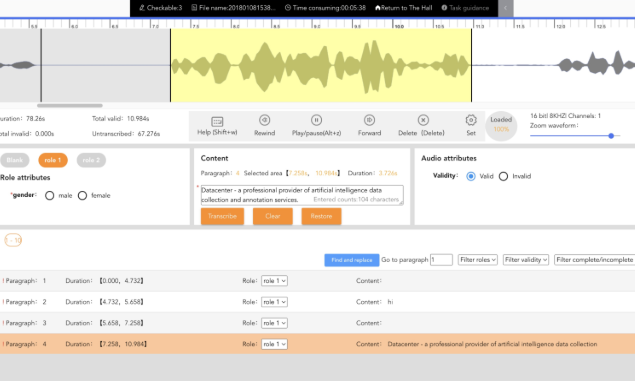
Our platform supports various types of speech data labeling,
such as speech segmentation, noise annotation, Speech
annotation and speaker role labeling, and has built-in
human-computer interaction semi-automatic labeling and
quality inspection functions, increasing labeling efficency by
over 30% per annotator.

Global resource pool. Support multiple
scenarios

NDA Guaranteed, Data
destroyed upon delivery

Support human-machine
interaction labeling

Multi-round quality
inspection process

High Quality with ISO9001
Certified Process

Obtained ISO27701,
ISO27001 certification

Be the first to receive Nexdata latest product releases, data solutions and enterprise news.





