➤ Tencent - ZhiTing hearing aid
It is essential to optimize and annotate datasets to ensure that AI models achieve optimal performance in real world applications. Researcher can significantly improve the accuracy and stability of the model by prepossessing, enhancing, and denoising the dataset, and achieve more intelligent predictions and decision support.Training AI model requires massive accurate and diverse data to effectively cope with various edge cases and complex scenarios.
➤ Nexdata's AI data services
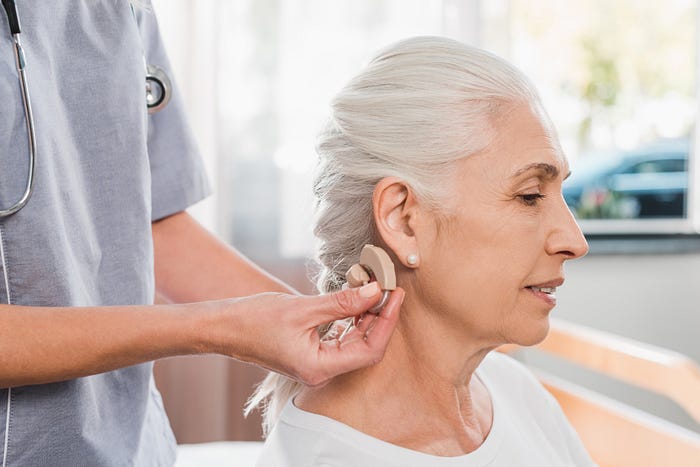
Recently, Tencent released a completely self-developed hearing aid core algorithm solution, jointly developed with hearing aid manufacturer ZhiTing Technology, and launched the ZhiTing (Tencent Teana inside) hearing aid “Public Welfare Helping the Elderly”. With the help of AI algorithms, this hearing aid improves the clarity and intelligibility of speech in complex scenarios by 85%, and has the characteristics of “low latency, low power consumption, and good sound quality”.
According to the World Health Organization, 5% of the global population, or 466 million people, suffer from hearing impairment, of which 34 million are children. In China, there are more than 27 million hearing-impaired people. Hearing impairment not only affects daily communication, but also leads to autism, irritability and other negative emotions in people with hearing disabilities, resulting in a decline in the quality of life and family conflicts.
In the past, hearing aids required a particularly large power consumption to reduce noise, which led many hearing aid manufacturers to abandon the noise reduction function in order to ensure the longevity of hearing aids. Putting the AI noise reduction algorithm into the hearing aid can achieve better noise reduction without reducing the use time of the hearing aid.
With 11 years’ experience for AI data servies, Nexdata owes multi-scenes and multiple recording device noice data to help AI algorithms perform better in speech enhancement.
101 Hours — Scene Noise Data by Voice Recorder
The data is multi-scene noise data, covering subway, supermarket, restaurant, road, airport, exhibition hall, high-speed rail, highway, city road, cinema and other daily life scenes.The data is recorded by the professional recorder Sony ICD-UX560F, which is collected in a high sampling rate and two-channel format, and the recording is clear and natural. The valid data is 101 hours.
20 Hours Microphone Collecting Radio Frequency Noise Data
The data is collected in 66 rooms, 2–4 point locations in each room. According to the relative position of the sound source and the point, 2–5 sets of data are collected for each point. The valid time is 20 hours. The data is recorded in a wide range and can be used for smart home scene product development.
➤ 1,297 Hours Scene Noise Data
531 Hours — In-Car Noise Data by Microphone and Mobile Phone
531 hours of noise data in in-car scene. It contains various vehicle models, road types, vehicle speed and car windoe close/open condition. Six recording points are placed to record the noise situation at different positions in the vehicle and accurately match the vehicle noise modeling requirements.
10 Hours — Far-filed Noise Speech Data in Home Environment by Mic-Array
The data consists of multiple sets of products, each with a different type of microphone arrays. Noise data is collected from real home scenes of the indoor residence of ordinary residents. The data set can be used for tasks such as voice enhancement and automatic speech recognition in a home scene.
1,297 Hours — Scene Noise Data by Voice Recorder
Scene noise data, with a duration of 1,297 hours. The data covers multiple scenarios, including subways, supermarkets, restaurants, roads, etc.; audio is recorded using professional recorders, high sampling rate, dual-channel format collection; time and type of non-noise are annotated. this data set can be used for noise modeling.
End
If you need data services, please feel free to contact us at info@nexdata.ai.
In the development of artificial intelligence, the importance of datasets are no substitute. For AI model to better understanding and predict human behavior, we have to ensure the integrity and diversity of data as prime mission. By pushing data sharing and data standardization construction, companies and research institutions will accelerate AI technologies maturity and popularity together.






 Recent
Recent
 Previous
Previous Next
Next




